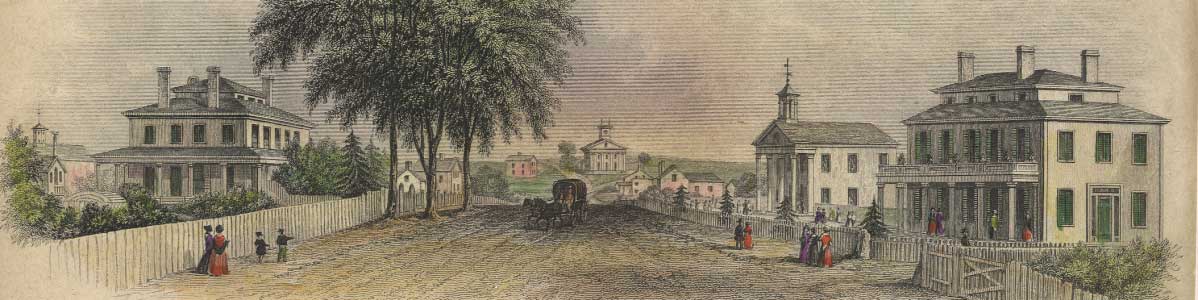
Eliza Baylies Wheaton and her husband Laban Morey Wheaton lived in a community that lay at the border of the changing agricultural and industrial economies of the early nineteenth century. Situated between the developing industrial centers of New Bedford and Fall River in Massachusetts and Pawtucket and Cumberland in nearby Rhode Island, Norton was a site where the Wheatons and other local landowning families diversified their economic pursuits through such industrial enterprises as cotton mills and iron foundries.
In the 1830s, these families mobilized their wealth to support the creation of local institutions. The Wheatons were instrumental in the founding of the Trinitarian Congregational Church in 1832, and they were involved in the temperance and abolition movements. In addition to their ties to other members of the town’s elite, the Wheatons were employers of household workers and farm laborers as well as the women and men who worked in the cotton mills and straw hat manufactories owned by Laban Morey Wheaton and his business associates.
How can digitization of primary sources contribute to the practice of history? In spring 2010, scholars met at the University of Virginia in a conference to discuss The Shape of Things to Come.
At University College London, Transcribe Bentham invites the public to participate in digitizing some of the papers of philosopher Jeremy Bentham.


Poster from a Digital Humanities 2010 session: Digitizing Ephemera and Parsing an 1862 European Itinerary (pdf)